1.2. OpenCL Design
K-mean clustering algorithm is very time consuming algorithm because it goes through all of the data set and finds the distance of each data to centroid of all data. For calculations like these, FPGAs are great target. The Intel® FPGA SDK for OpenCL™ provides a faster solution for you to benefit the flexibility of FPGA platforms and accelerate the clustering process for huge number of unlabeled input data.
In this section, we take the previously described algorithm, and implement it as a series of OpenCL* kernels. Initial centroids for k clusters are chosen on the host code and then passed into an OpenCL* kernel running on an FPGA. Therefore, you can modify the host code with a method that you like to use to initialize the centroids. All the data is passed to the initial kernel using global memory transfer.
The following diagram shows the data flow between the kernels.
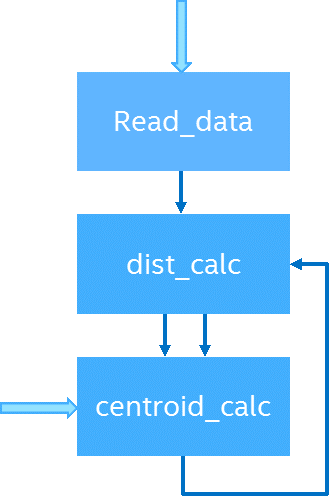
The first kernel (Read_data) reads input data from global memory and saves it locally for the iterations of the algorithm that follow. Through an internal channel, this data is passed to next kernel, which is an autorun kernel, in packets of 16 input data.
The next kernel (dist_calc) calculates the distance of each data point to all centroids and labels the data in the cluster with the minimum distance. It also calculates the sum of all the data labeled in the same cluster.
The generated data at this level is passed to the next kernel (centroid_calc) through an internal channel. In this kernel, the sum of data in each cluster is read from the internal channel and added until all of the data is processed. Then, the new centroids are calculated as an average of all of the data categorized in each cluster.
If the distance of the new centroids to the previous one is less than the acceptable error, the data was successfully clustered and the kernel exits.
If the error is not acceptable, the new centroids are sent to the dist_calc kernel again through an internal channel for the next iteration.