By: Yan Meng (yan.meng@intel.com), with contribution from Fillipe D.M. de Souza, Shahzad Butt, Hubert de Lassus, Yongfa Zhou, Yong Wang, Tomás Aragón González, Jingyi Jin, and Flavio Bergamaschi
Fully Homomorphic Encryption (FHE) is one of the leading techniques—along with trusted execution environments such as Intel® Software Guard Extensions (Intel® SGX), secure multiparty computation, and differential privacy—which addresses the escalating privacy concerns from the widespread use of various aspects of cloud computing [1]. Regarded as the holy grail of cryptography, FHE enhances users’ privacy by performing arbitrarily complex computations on encrypted data without having access to or knowing the contents of decrypted data. FHE opens a multitude of practical and real-world applications by enabling cloud computing without compromising data security, privacy, or confidentiality. This has practical applications ranging from analyzing sensitive financial and medical data to enabling private query searches.
While FHE has advanced rapidly in both theory [3] and implementation [5, 6, 7] since Craig Gentry’s mathematical breakthrough in constructing the first plausible FHE scheme [4], the substantial computational cost—based on large integers and high memory bandwidth requirements—has limited the FHE technique from being adopted in practice until recently [8, 9, 10, 11].
Leveraging a plethora of computational resources and high-bandwidth, distributed, on-chip memories, we have designed the high-performance Intel® Homomorphic Encryption Acceleration Library for FPGAs. The Intel® Homomorphic Encryption Acceleration Library for FPGAs enables developers to accelerate critical fully homomorphic encryption operations, such as dyadic multiplication, keyswitch, forward negacyclic number-theoretic transform, and inverse negacyclic number-theoretic transform. Intel has released the library under the open source Apache 2.0 license to ignite further research and development in this area.
Fully Homomorphic Encryption Operations in a Nutshell
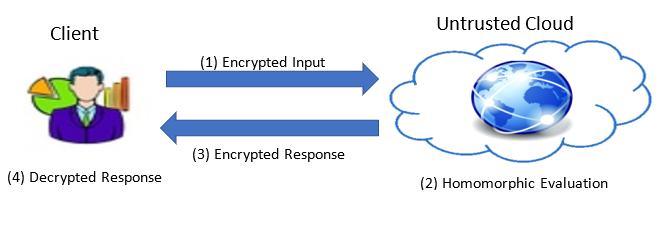
Figure 1: A simple example of outsourcing computation to an untrustworthy third party using fully homomorphic encryption.
Figure 1 shows a typical FHE application. A client’s input message, usually in the form of a vector, is first encoded into a plaintext polynomial, which is then encrypted into a ciphertext consisting of two polynomials, for example, \(c = (a, b)\), of N integer coefficients modulo some big integer Q. After performing ciphertext computations homomorphically, either through locally or via remote cloud, the user receives an encrypted response, and then decrypts and decodes the response to learn the result of the computation. The data and computation remain encrypted throughout the entire process.
FHE differs from Partial Homomorphic Encryption schemes [4], where only a single type of operations can be performed on encrypted data (ciphertext), for instance, multiplication or addition. Fully homomorphic encryption schemes can support multipliable operations, both multiplication and addition, allowing more operations to be evaluated over ciphertext.
Homomorphic multiplication usually requires two steps. First, the four input polynomials are multiplied through a dyadic multiplication operation, and the results are assembled as shown below:
\(𝑐 = (a_0, b_0) ● (a_1, b_1) = (𝔞_0𝔞_1, 𝔞_0𝔟_1 + 𝔞_1𝔟_0, 𝔟_0𝔟_1) = (ci_2, ci_1, ci_0).\)
The result 𝑐 can be viewed as a special intermediate ciphertext encrypted under a different secret key. The second step, which is called relinearization, performs a Keyswitch operation to produce a final two-polynomial ciphertext encrypted with the original secret key.
Multiplying two polynomials requires convolving their coefficients, which is an expensive \((O(N^2))\) operation. To speed up the convolution, polynomial multiplications are often conducted with Number-Theoretic Transform (NTT) [12], which is a Fast Fourier Transform (FFT) over a finite field of integers (with the complexity of \((O(N log N))\). In fact, FHE implementations usually store polynomials in NTT format rather than their coefficient forms, and polynomial multiplication are carried out in NTT domain by first mapping two inputs to their NTT forms, then performing element-wise multiplication, and finally executing inverse NTT on its result.
Based on research [3] and past implementations [8, 10, 11], Keyswitch is an expensive operation that dominates the computation time in relinearization, ciphertext rotation, and bootstrapping operations. The computation pipeline for Keyswitch consists of highly computational components, such as NTT, INTT, dyadic multiplication, and modulus switching, which are executed in multiple iterations [8, 10, 11].
Homomorphic addition of ciphertexts \(𝑐_0 = (𝔞_0, 𝔟_0)\) and \(𝑐_1 = (𝔞_1, 𝔟_1)\) is computed simply by adding their corresponding polynomials: \(𝑐 = 𝑐_0 + 𝑐_1 = (𝔞_0 + 𝔞_1, 𝔟_0 + 𝔟_1)\). In NTT domain, it corresponds to element-wise addition of two inputs from NTT transform.
Intel Fully Homomorphic Encryption Acceleration Library for FPGAs
The Intel Fully Homomorphic Encryption Acceleration Library for FPGAs is designed to accelerate computationally intensive fully homomorphic encryption operations. This library consists of seven modules, shown in Figure 2. Three are essential:
- High performance FPGA kernels to accelerate common computationally intensive FHE operations.
- An asynchronous host runtime to provide high system utilization and scalable design to accelerate with multiple FPGA cards.
- Host APIs to provide high level C++ interfaces for integrating with common FHE libraries and accelerating FHE library operations on FPGAs.
In addition, the library includes four utility modules. The tests and benchmarks are used to test the functionality and to benchmark the performance of the internal library components, while the documents and examples are intended to help users understand the library’s internal design as well as to facilitate the integration of the FPGA library into third-party FHE libraries, upon which privacy-preserving applications are commonly built.
The library has been validated on a system hosting an Intel® PAC D5005 (Intel® Stratix® 10 GX 2800), and Terasic DE-10 Agilex (Intel® Agilex™ F014) PCIe cards.
The following sections provide a detailed overview of the key components of the library and its operation, high performance FPGA kernels, asynchronous host runtime, and host APIs.
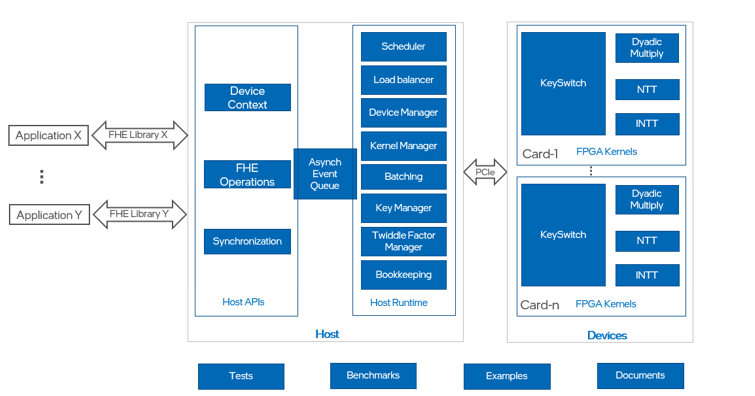
Figure 2: Architecture of Intel Fully Homomorphic Encryption Acceleration Library for FPGAs
High Performance FPGA Device Kernels
The list of operations used in homomorphic encryption that are provided in the Intel Homomorphic Encryption Acceleration Library for FPGA open source release includes:
- Keyswitch
- Dyadic multiplication
- The forward negacyclic number-theoretic transform (NTT)
- The inverse negacyclic number-theoretic transform (INTT)
The operations are identified as computationally intensive hotspots by profiling a set of applications and benchmarks with Intel® VTune™ Profiler on Intel CPUs. The FPGA kernel designs and optimizations are then performed on each individual operation based on the following design methodology:
- Common computational logics of the operations, such as modular addition, modular multiplication, are first extracted and optimized with Intel High Level Synthesis Compiler as library components.
- Then, the library components are integrated into a kernel design, which is implemented in Intel® FPGA SDK for OpenCL, and the design is optimized to achieve the best performance in terms of throughput and latency and stored in a FPGA bitstream for the runtime to consume.
To optimize a kernel, we iterate the following three-step process until the kernel reaches its targeted performance.
- Investigate the reports generated by the OpenCL compiler, aoc, and the high-level synthesis compiler, i++.
- Identify the required code changes for further optimization.
- Validate the code changes.
Within each computational component of a kernel, the main optimization techniques involve loop fusion, loop unrolling, loop pipelining, and double buffering. We achieved better latency and data locality with data prefetching, memory coalescing, BRAM banking, bank conflicts resolution through data reordering and replication, data packing, data reuse, and burst memory access. To achieve the best overall kernel throughput, we also focus on the balance of the throughputs and the selection of data transfer interfaces through on-chip channels or shared on-chip memories between components within a kernel.
We developed the kernels to be parameterizable for different use cases. For example, a kernel can be parameterized to support different data vector widths for parallel computation. The same kernel can also be instantiated multiple times based on the available FPGA resources. Multiple instances of the same kernel share the same control and data dispatch logic and execute in lockstep to enable higher throughput, when Fmax does change significantly. To ensure the correctness of the functions in Intel HE Acceleration Library for FPGAs, the kernels currently support the following configurations:
- Dyadic multiplication supports the ciphertext polynomial size of 1024, 2048, 4096, 8192, 16384, and 32768.
- Keyswitch supports the ciphertext polynomial size of 1024, 2048, 4096, 8192, and 16384, the decomposed modulus size of no more than seven, and all ciphertext moduli to be no more than 52 bits.
- The standalone forward and inverse negacyclic number-theoretic transform functions support the ciphertext polynomial size of 16384.
This distribution provides an experimental integrated kernel implementing the dyadic multiplication and keyswitch in one bitstream, as well as separate standalone kernels implementing one of the primitive functions in a bitstream. All the FPGA kernels work independently of each other. The standalone kernels allow testing and experimentation on a single primitive. For example, Keyswitch and dyadic multiplication kernels are for high performance and the forward NTT, and the inverse NTT kernels are for experiments and functional testing only.
Asynchronous Host Runtime to Maximize Kernel Utilization
While optimized FPGA kernels provide the maximal throughput when all arithmetic units on the chips are used, this is hardly the typical case in practice. Often, users may find the chip is busy doing other things, such as synchronizing between different computation units, fetching data from the off-chip memory, or communicating data across units and chips. The main challenge is the utilization of the kernel, which provides the practical number of operations users can get per second. To increase the kernel utilization, computational overhead must be minimized. We designed the FPGA host runtime to predict and minimize the impact of those hardware events for all real-world scenarios.
To achieve high throughput and high scalability, the FPGA host runtime enables the efficient scheduling of host and device executions and the load balancing of multiple FPGA accelerator cards based on a push-pull model of computation. All connected devices are managed by a device manager. Through a thread-safe task queue, the host pushes computation jobs to the runtime queue, and the device manager pulls jobs from the queue and dispatches them to a target FPGA device based on the device’s availability. Both host pushing and device pulling mechanisms are implemented with asynchronous interfaces to maximize the device utilizations and to provide the linear scaling of target throughput with multiple accelerator cards.
Besides pipelining compute components of host and devices, the host runtime also supports batching of the same type of computations to reduce input/output (I/O) communication through PCIe and the overlapping of I/O communication and component execution. Through the host runtime kernel manager, users can load and experiment with different kernels on FPGAs, either as integrated kernels or a standalone kernel. While an integrated kernel may have a smaller design Fmax, the benefit of using an integrated kernel is to avoid the time-consuming step of reconfiguring the FPGA with different kernel bitstreams. With the provided host runtime, users can experiment based on their applications to find their best system throughput. Users can also visualize the host-FPGA interactions with Intel VTune Profiler and measure kernel utilization.
To provide the high throughput twiddle factor accesses of for on-chip NTT and INTT computations, the host runtime manages the twiddle factor constants by pre-calculating their values based on the input chain of moduli and loading them onto on-chip memories through one-time I/O communication. Besides, for Keyswitch, the host runtime provides mechanisms for restructuring and packing the switching keys into bit fields and storing them efficiently in DDRs to provide the best DDR access throughput during Keyswitch calculation.
Host APIs
Host C++ APIs provide interfaces for integrating the FPGA library with third party FHE libraries and accelerating its critical operations on FPGAs. It consists of APIs for setting up and destroying FPGA device context, APIs for FHE operation acceleration on FPGAs through synchronous or asynchronous executions, and APIs for synchronizing computation results back to the host application. Library integration and host API examples can be found in the examples directory of the open source release.
Conclusions
FHE provides developers with a powerful tool to address privacy concerns associated with the ever-increasing demands of cloud computation. The Intel Homomorphic Encryption Acceleration Library for FPGA is designed to address this concern by providing practical solutions to many of the challenges associated with developing FHE applications. The design achieves significant speedup in terms of throughput and latency measured from Intel® Agilex™ devices. With more capable Intel FPGAs on the horizon, the library is expected to deliver higher throughput and lower latency to accelerate more FHE applications.
This distribution is the beginning of a journey that Intel hopes to travel with the cryptographic community. Intel invites developers to try out our opensource releases, and we welcome feedback and contributions to new kernels, optimizations, API extensions, and high-level FHE library integration. In the future, we plan to support high-level operations and to enable the upper software stack integration to accelerate diverse customers’ use cases and workloads.
References
- Cryptographic Techniques and the Privacy Problems they Solve, https://leapyear.io/resources/blog-posts/smpc-fhe-dp/
- Intel® Software Guard Extensions (Intel® SGX), https://www.intel.com/content/www/us/en/architecture-and-technology/software-guard-extensions.html
- A. Acar, H. Aksu, A. Uluagac, M. Conti, A Survey on Homomorphic Encryption Schemes: Theory and Implementation, ACM CSUR 2017 ePrint Archive, https://arxiv.org/abs/1704.03578
- C. Gentry. Fully homomorphic encryption using ideal lattices. In Proceedings of the forty-first annual ACM symposium on Theory of computing, 2009.
- S. Halevi and V. Shoup. Design and implementation of helib: a homomorphic encryption library. Cryptology ePrint Archive, 2020. https://eprint.iacr.org/2020/1481.pdf
- Microsoft SEAL (release 4.0). https://github.com/Microsoft/SEAL, Mar 2022. Microsoft Research, Redmond, WA.
- PALISADE Lattice Cryptography Library (release 1.11.6). https://palisade-crypto.org/, Feb 2022.
- F. Boemer, S. Kim, G. Seifu, F. de Souza, V. Gopal, et al. Intel HEXL (release 1.2.4). https://github.com/intel/hexl, 2022.
- S. Kim, W. Jung, J. Park, and J. Ahn. Accelerating number theoretic transformations for bootstrappable homomorphic encryption on gpus. In IEEE International Symposium on Workload Characterization (IISWC), 2020.
- M Sadegh Riazi, K. Laine, B. Pelton, and W. Dai. HEAX: An architecture for computing on encrypted data, ASPLOS, 2020, Lausanne, Switzerland
- A. Feldmann, N. Samardzic, A. Krastev, S. Devadas, R. Dreslinski, K. Eldefrawy, N. Genise, C. Peikert, D. Sanchez, F1: A Fast and Programmable Accelerator for Fully Homomorphic Encryption, IEEE/ACM MICRO, 2021
- D. Harvey. Faster arithmetic for number-theoretic transforms. Journal of Symbolic Computation, 2014