Introduction
In this article, I go over the ins and outs of using persistent memory as a substitute for traditional storage media—such as hard disk drives (HDDs) or solid-state drives (SSDs)—to speed up your I/O workloads. One of the goals is to clear the waters in terms of terminology. My hope is that, by explaining the core differences (such as those related to the software stack) between traditional storage technologies versus persistent memory used as storage, you will be well-armed to take advantage of what persistent memory has to offer. In the second part of the article, some performance numbers are presented that compare the different ways to do I/O and showcase the impressive performance that can be achieved with Intel® Optane™ persistent memory. Finally, I present one last set of experiments that demonstrates the importance, for the sake of performance, of using huge pages when memory mapping from userspace.
This article assumes that you have a basic understanding of persistent memory concepts and are familiar with general Persistent Memory Development Kit (PMDK) features. If not, please visit Persistent Memory Programming on the Intel® Developer Zone web site, where you will find the information you need to get started.
Block Access Versus Byte Access
The fact that CPU and storage are separated has some implications; the most important being the fact that the CPU cannot talk directly to the storage subsystem. By directly, I mean that an instruction executed by the CPU cannot issue a read/write operation directly against a storage device. Instead, the CPU needs to send requests to a device over an I/O bus using a protocol, for example, PCIe*. Since this communication is handled by a driver, a context switch to the operating system (OS) is inevitable. To hide some of the latencies involved, I/O requests are made in blocks of some predetermined large size such as 4 kibibytes (KiB) (4096 bytes). Moreover, data needs to be copied to an intermediate dynamic random-access memory (DRAM) buffer in userspace (this is different from the page cache), so the application can access it using regular load and store instructions.
The previous paragraph describes block access. In contrast to that, we have byte access, in which the CPU can talk directly to the media. In some places, you see this type of media being referred to as byte-addressable. An example of byte-addressable media is double data rate (DDR) memory. Any of the persistent memory (PMEM) technologies that sit on the memory bus such as non-volatile dual in-line memory modules (NVDIMMs) or Intel® Optane™ memory modules are also byte-addressable. Figure 1 shows, coarsely, the difference between these two modes of access at the hardware level. Figure 2 does the same but at the software level.
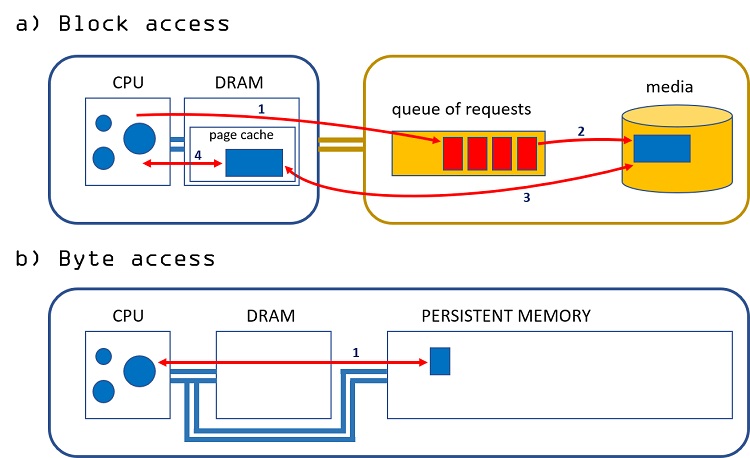
Figure 1. The difference at the hardware level between block access (a) and direct access (b).
The numerals in Figure 1 specify different steps in the I/O path. In the case of block access, Figure 1a, all I/O operations require the CPU to queue requests in the device (step 1), which are later run by the device itself (step 2). The latter may trigger a direct memory access (DMA) operation (step 3) to read blocks from DRAM and write them to the storage media, or the other way around. The page cache can be bypassed, as we will see later; for the sake of simplicity, I consider only the case with page cache in this figure. In step 4, the application simply reads the data if the operation was a read or writes the data before issuing a write operation.
Contrast that with byte access, Figure 1b. In this case, the CPU can directly access the data in the device at cache line granularity and in a single step.
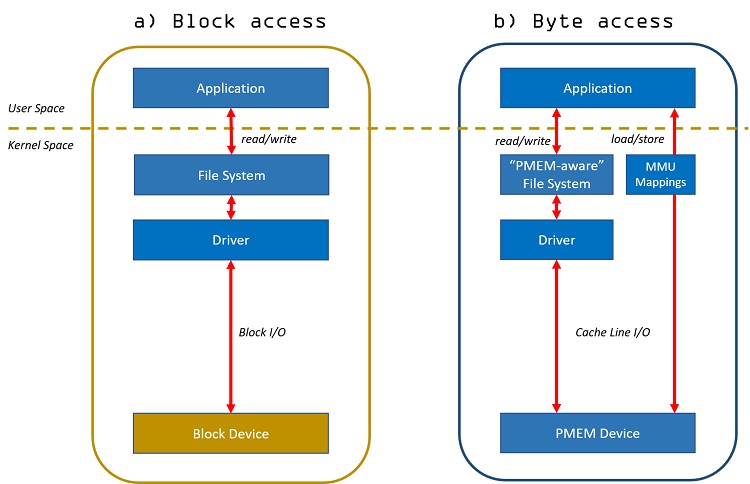
Figure 2. Difference at the software level between block access (a) and direct access (b).
In Figure 2, we can see the two main differences between block and byte access at the software level. The first difference is that all I/O done in Figure 2b is always done at cache line granularity, even when blocks are read or written through a file system. The second is that it is possible to bypass the OS by memory mapping a file. The application can, in that case, access the file through loads and stores, as well as flush data out of the CPU caches, directly from userspace.
Figures 1 and 2 don’t cover all possible ways in which applications can do I/O, of course, although they are good enough for the sake of this discussion. As an example, consider the case of an application that memory maps a file in the block access case, Figure 2a, and then accesses the data using load and store instructions. Even in that case, the file system still needs to fetch those blocks from the device and store them in DRAM. In fact, accessing bytes from a non-cached (but mapped) block is essentially the same as issuing a read request to the device for that whole block. Also, the file system is involved when the application wants to flush pending writes out of DRAM buffers to make sure they are persistent.
Before moving on, let’s summarize the important lessons to take away from this section
In block access:
- Access to data in the media is done in blocks.
- The CPU cannot access the data directly.
- The OS is always needed in the I/O path.
In byte access:
- Access to data in the media is always done at cache line granularity, even when I/O is done through a file system calling read/write. Operations larger than a cache line are broken up.
- The CPU can access the data directly.
- Context switches to the OS can be avoided by memory mapping files, which allows the user to issue loads, stores, and flush data out of the CPU caches completely from userspace.
Traditional I/O Over Persistent Memory
It is possible to use persistent memory as storage without changing your application or file system, as long as you have the proper drivers and tools installed in the system.
There is a catch, however. Remember from the previous section that all I/O done against persistent memory is done at cache line granularity. This means that all I/O operations are converted by the driver into memory copies. Because the x86 architecture only guarantees write atomicity for 8 bytes at a time, applications and file systems that rely on write atomicity at the block/sector level can get their data corrupted by torn sectors in the event of a crash or power failure.
To avoid such a scenario, we can create namespaces in sector mode. In this mode, the driver maintains a data structure called the Block Translation Table (BTT) to make sure torn sectors do not happen. To learn more about BTT, read the article Using the Block Translation Table for sector atomicity. One of the implications of using sector mode is that all I/O needs to go through the driver, which means that context switches to the OS are again inevitable.
To create a namespace in sector mode, run the following ndctl command:
# ndctl create-namespace -m sector
For more information about persistent memory configuration, refer to the NDCTL user guide.
After creating the namespaces, new devices will appear as /dev/pmemXs, where X is a numeral specifying a particular namespace. These devices can be formatted with any file system or partitioned using tools such as fdisk. You can also use the device directly without a file system.
I/O Without Sector Atomicity
Maintaining the BTT data structure incurs a performance penalty in both time and space. We can think of the BTT as a very simple file system, which means that using a file system on top of BTT is akin to having two file systems running one on top of the other.
Modern file systems, such as ext4 and xfs in Linux* are persistent memory -aware since Linux kernel version 4.2 and hence will work fine with persistent memory media, which does not provide write sector atomicity. The mode to avoid the BTT is called fsdax. To create a namespace in fsdax mode, run:
# ndctl create-namespace -m fsdax -M mem
Once namespaces are created, the new devices will appear as /dev/pmemX, where X is a numeral specifying a particular namespace. These devices can also be partitioned, but they should only be formatted with a persistent memory -aware file system, or else data corruption could occur.
Keep in mind, the protection that persistent memory-aware filesystems provide only relates to the file system metadata, and never the application’s data. If your application relies on write atomicity for blocks of data, you may need to redesign your application. Likewise, if you use the device without a file system (as some databases do), the application will also need to be aware of this fact.
Avoiding the Page Cache
When the performance gap between storage media and memory is large, that is, multiple orders of magnitude, having a page cache makes a lot of sense, especially for applications that do I/O in large sequential chunks.
Persistent memory devices, on the other hand, have performance characteristics that are very close to those of DRAM; usually within the same order of magnitude or, at worst, one order of magnitude difference. This performance characteristic can make having a cache counter-productive, especially in the case of small and random I/O. Copying a whole block of 4KiB—for example, from persistent memory to DRAM—is costly, and that cost needs to be justified by a strong spatial and temporal locality.
It can be argued that a lot of applications do I/O by buffering large sequential chunks to optimize for slow storage. This way of doing I/O may necessitate large amounts of DRAM. Transforming the way these applications do I/O can help reduce the DRAM footprint and hence the total cost of ownership (TCO), although that analysis is out of the scope of this article.
To configure a persistent memory-aware file system to bypass the page cache we need to specify the option “dax” when mounting it. The namespace should have been created as fsdax:
# mount -o dax /dev/pmem0 /mountpoint
Here, dax means direct access from the point of view of applications (remember that the CPU always has direct access to persistent memory devices). The dax option, apart from bypassing the page cache, allows applications to access the persistent media directly from userspace when files are memory-mapped. Bypassing the page cache is just a byproduct of dax.
It is important to point out that the dax option for fsdax was designed for programming against persistent memory devices following the NVM Programming Model (NPM) standard developed by the Storage and Networking Industry Association (SNIA). In other words, it was designed specifically to allow applications to access bytes in place through a direct pointer to the media, instead of copying them to a local buffer first. In fact, doing the latter may just produce an extra, and probably unnecessary, data copy between two memory devices (DRAM to PMEM) on the same bus.
Using dax without a file system is also possible. This mode is called devdax and has limited functionality; it can only be used effectively by memory mapping the device. To create a namespace in devdax mode, run:
# ndctl create-namespace -m devdax -M mem
Once namespaces are created, new devices will appear as /dev/daxY, where Y is a numeral specifying a particular namespace.
Finally, it should be mentioned that bypassing the page cache has always been possible with traditional file systems by opening files with O_DIRECT. The difference here is that in the traditional case:
- All I/O is still done to/from user-space buffers (no direct pointers to media).
- The OS is still in the I/O path.
Although dax can be considered a better way to bypass the page cache in general, whether you should use dax or O_DIRECT may depend on your application.
Avoiding the CPU Caches
Even if we avoid the page cache in DRAM, we still have the CPU caches. Remember that, in persistent memory, all I/O accesses are memory copies. What this means is that the CPU is always involved.1 If the CPU is involved, all loads will bring data from the lower levels of the memory hierarchy to the CPU caches, and all stores will write to the CPU caches first, until they are flushed (or evicted) back to the persistent media.
There are scenarios where writing to CPU caches may produce undesired results. Such is the case for large sequential writes, particularly in those cases where the data written to persistent memory is not going to be used soon. This is a problem because the caches will evict data that have real temporal locality just to accommodate one-time stores. This is generally known as polluting the cache. Furthermore, writing to CPU caches first may transform sequential writes into random ones after the writes—either evicted or flushed away—finish percolating through all the cache levels.
To avoid this problem and bypass the CPU caches completely, we need to use non-temporal writes. Here, non-temporal references the fact that the data we are writing does not have temporal locality. The following code snippet shows an example of how to write 32 bytes using non-temporal stores. In particular, the code uses Intel® Advanced Vector Extensions (Intel® AVX) instructions through the Intel® Intrinsics Guide API:
_mm256_stream_si256((__m256i *)destination_pointer, source_register);
For more information about these instructions, refer to the Intel software developer manuals.
About Performance
Now, let’s see some performance numbers. Understand that these experiments are meant to be illustrative and not exhaustive. The performance comparisons are performed using synthetic workloads only: 100 percent random reads and 100 percent random writes.
Due to persistent memory’s low latencies—as compared against traditional HDDs and SSDs— and the lack of a queue of requests in the device (see Figure 1), only synchronous I/O is recommended. Doing I/O in an asynchronous fashion adds extra software overhead and, as we have already discussed above and will see in the performance numbers shown below, persistent memory shifts the I/O bottleneck from hardware to software. If your application can’t wait for an I/O operation to complete even at low latencies, then asynchronous I/O makes sense. In that case, however, you may need to reevaluate if persistent memory is the right technology for your I/O needs as you will lose the media speed advantage.
All tests are done using the master of the Flexible I/O (FIO) tool downloaded on 07/17/2019 (commit fc22034; more details are presented in Appendix A), PMDK corresponding to master downloaded on 07/30/2019 (commit 19deecdaf3), and the XFS file system (see Appendix B for details about file system configuration). For more details regarding the testing platform, see the performance disclaimer at the end of this article.
Three sets of experiments are performed in the next three subsections. In the first set, the different ways of doing I/O are compared by fixing the accessed block size to 4 KiB (4096 bytes). In the second set, the ioengine is fixed to libpmem, and different block sizes are compared for the case of random reads. Finally, the last set of tests show the importance of using huge pages to fully exploit the performance capabilities of persistent memory.
Comparing All I/O Modes
In Figures 3 and 4, the different ways of doing I/O are compared by fixing the accessed block size to 4 KiB (4096 bytes). The workload is constrained to a single socket, with six DRAM DIMMs and six Intel Optane persistent memory modules configured in App Direct interleaved mode. All I/O is NUMA-aware (no I/O crosses sockets).
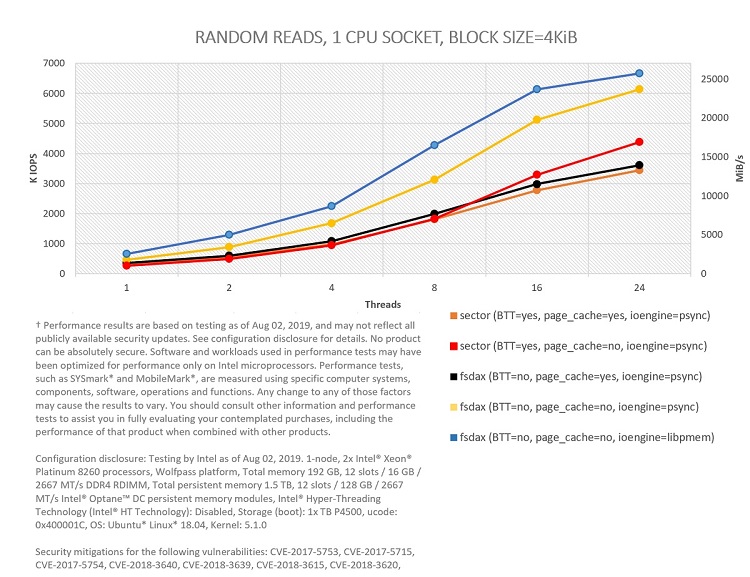
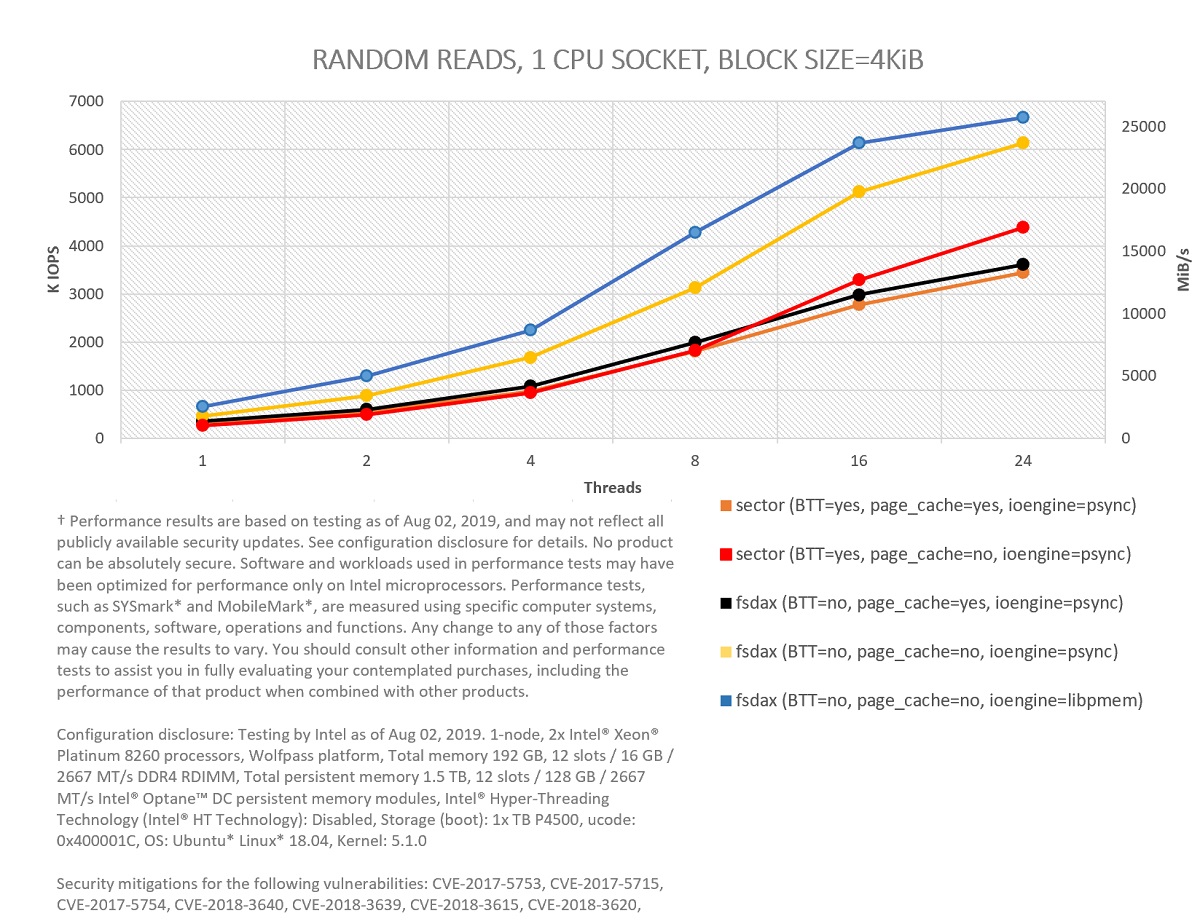
Figure 3: Comparing I/O modes in PMEM for 100 percent random reads in one CPU socket.
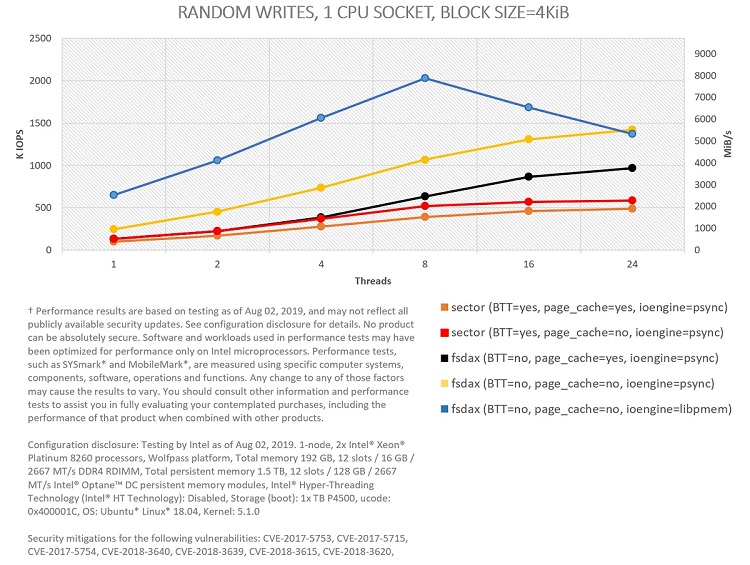
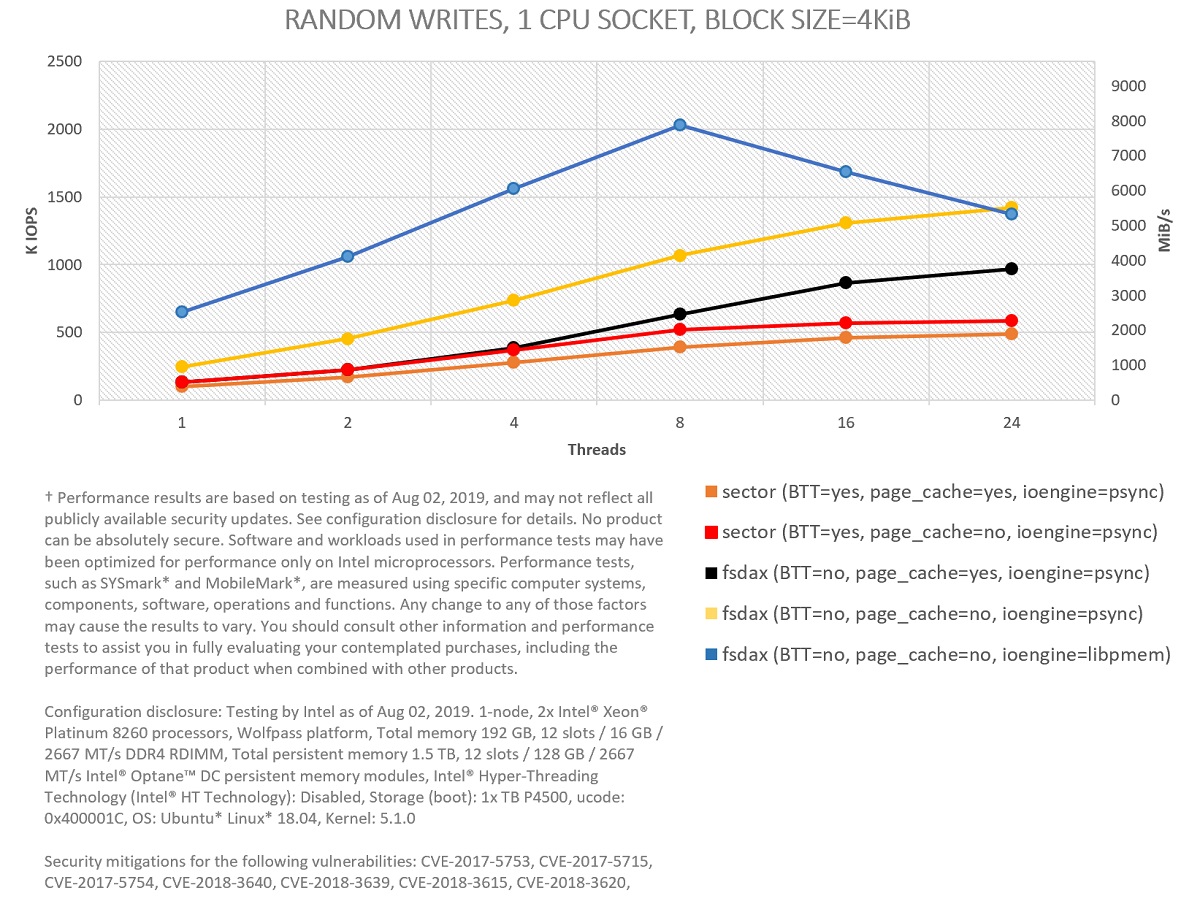
Figure 4: Comparing I/O modes in PMEM for 100 percent random writes in one CPU socket.
As shown, bypassing the page cache helps in both random reads and writes (yellow curves better than black curves, and red ones better than orange ones). O_DIRECT is used (FIO option direct=1) to bypass the page cache in sector mode (red curves), given that dax is not available.
Bypassing the OS using libpmem is also a good idea in almost all situations. The ioengine libpmem, which is part of PMDK, works by memory mapping files and accessing data through memory copies directly from userspace. The ioengine psync, on the other hand, context-switches to the OS through the pread() and pwrite() system calls. For the case of 4 KiB random reads, we get a peak with libpmem of close to 6.7 million input/output operations per second (MIOPS) and 25.4 gibibytes/sec (GiB/s) using 24 threads. For 4 KiB random writes, the peak with libpmem—2 MIOPS and 7.7 GiB/s—occurs with eight threads. For FIO write tests with libpmem, we also need to set the option direct=1. In this case, this option just indicates to the engine that non-temporal writes should be used.
Keep in mind that these tests are not designed to saturate the maximum possible read and write bandwidth of Intel Optane memory modules. For example, write tests are performed ensuring that every written block is fully persistent. This implies calling fdatasync() after every write (FIO option fdatasync=1) for psync.2 fdatasync() is not needed for libpmem (blue), since block persistency is already guaranteed by executing an SFENCE instruction right after issuing all the needed non-temporal writes.
If you are interested in raw performance numbers, a study published recently titled Basic Performance Measurements of the Intel Optane Persistent Memory Modules shows that you can get peak bandwidths of up to 39.4 GiB/s for reads and 13.9 GiB/s for writes using six interleaved Intel Optane memory modules within a single socket.
Focusing on the experiments that use the BTT, we can see the performance impact incurred to ensure sector atomicity. The impact is very clear for the tests bypassing the page cache (yellow versus red), although the difference between the tests using the cache (black versus orange) is also significant for the case of writes.
Latency Versus Bandwidth
In these experiments, the ioengine is set to fsdax (BTT=no, page_cache=no, ioengine=libpmem). Different block sizes are compared for the case of random reads. The whole system (two sockets) is used this time with 12 Intel Optane memory modules configured in App Direct interleaved mode.
Note: Interleaving does not work across sockets for App Direct, so two namespaces are created. I/O access is still NUMA-aware.
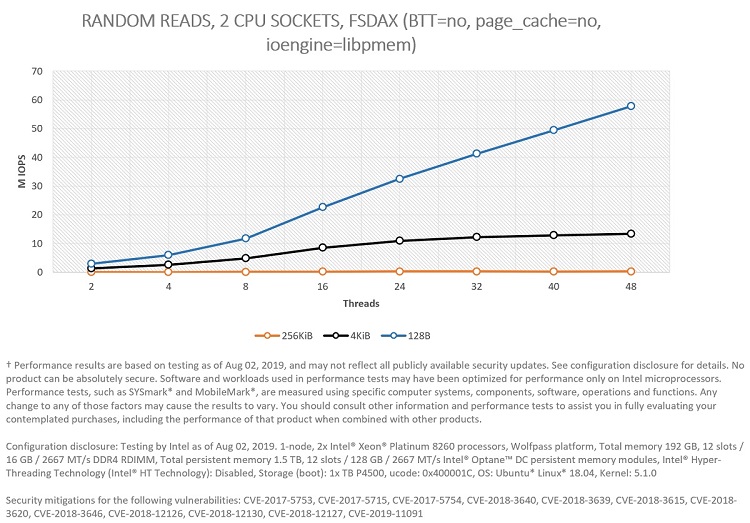
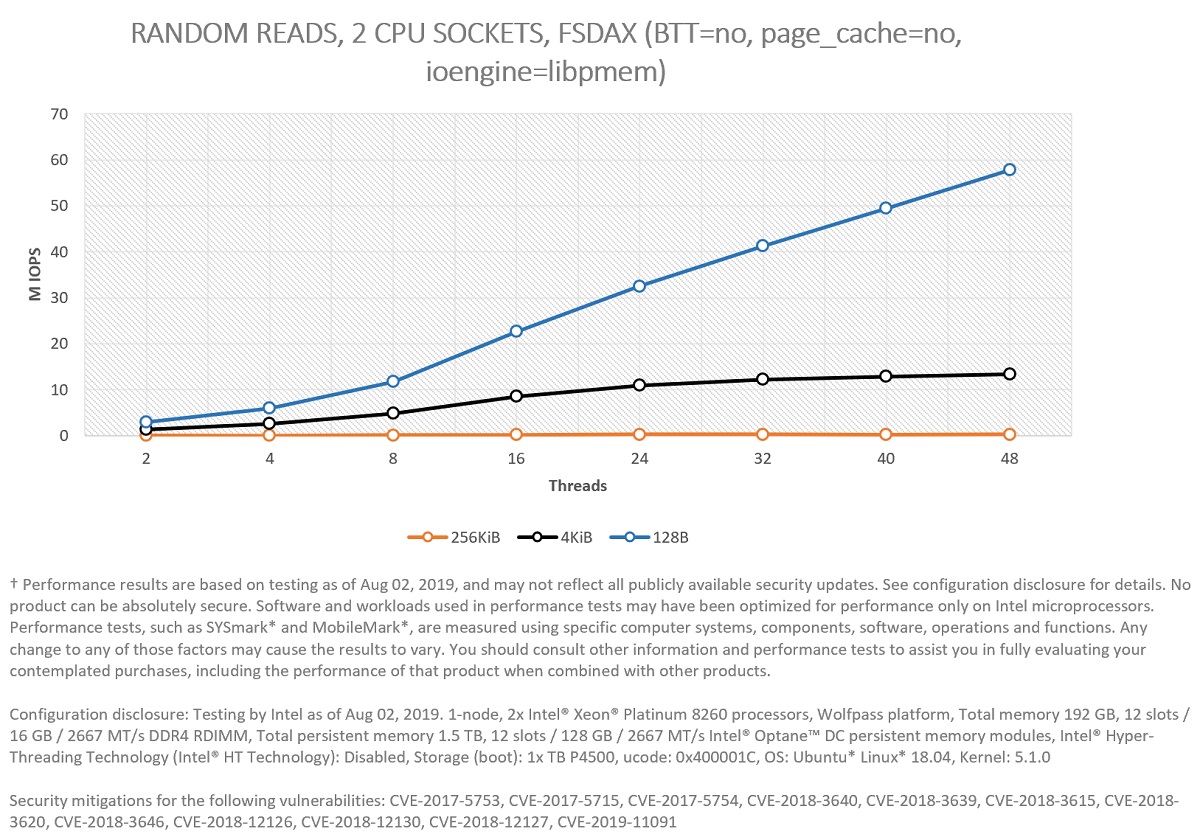
Figure 5. Comparing IOPS for block sizes for 100 percent random reads in two CPU sockets.
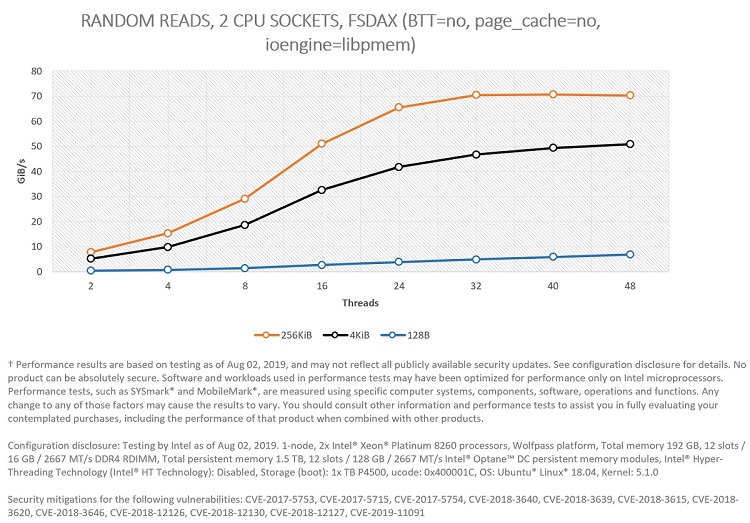
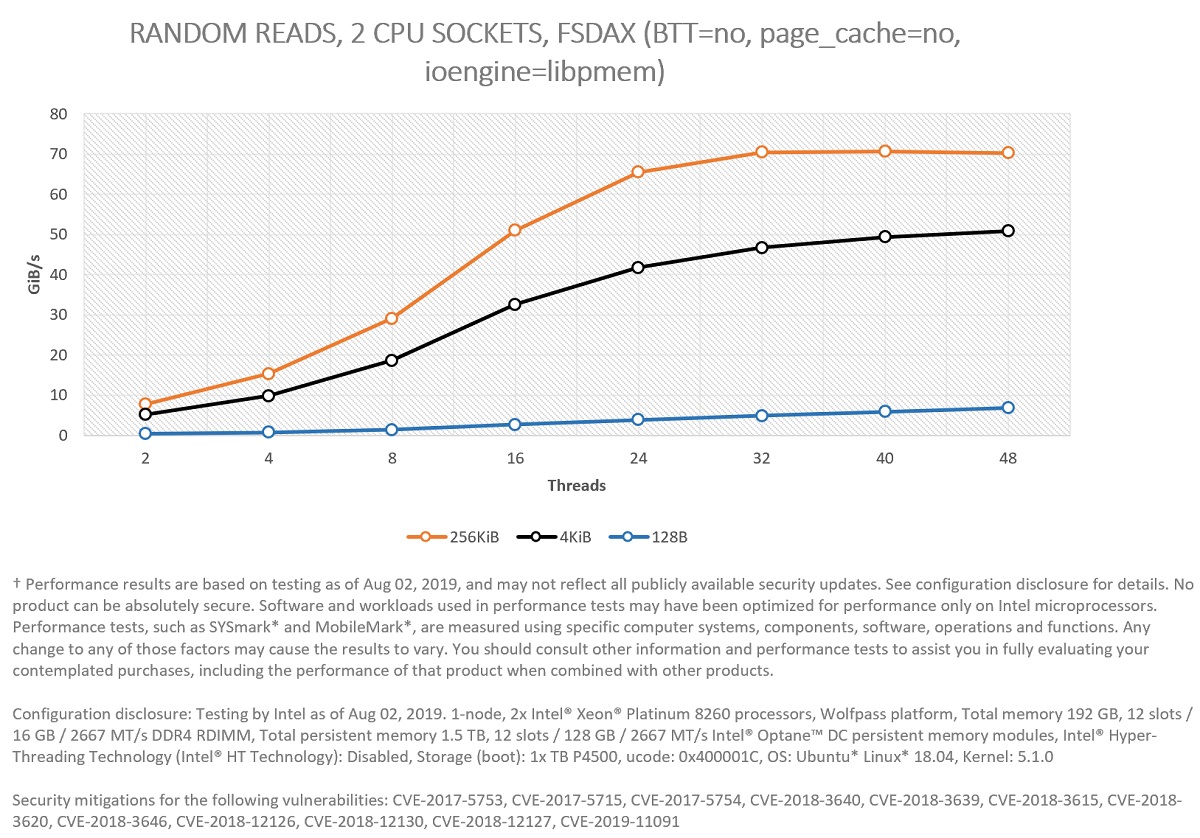
Figure 6. Comparing—in terms of GiB/s—block sizes for 100 percent random reads in two CPU sockets.
In this case, Figures 5 and 6 represent the same experiments but looked at from two different points of view: Latency (Figure 5) and bandwidth (Figure 6).
Figure 5 shows that the system can scale all the way to 57.8 MIOPS for random small accesses (128 bytes) using 48 threads (24 in each CPU socket), illustrating that Intel Optane memory modules are ideal for workloads/systems that require extremely fast response (latency of access is critical) to millions of requests per second for randomly distributed data access. This can also be visualized in Figure 7, where the p993 latency of access to persistent media is shown. As it is possible to see, p99 latency is always below one microsecond for 128 bytes blocks.
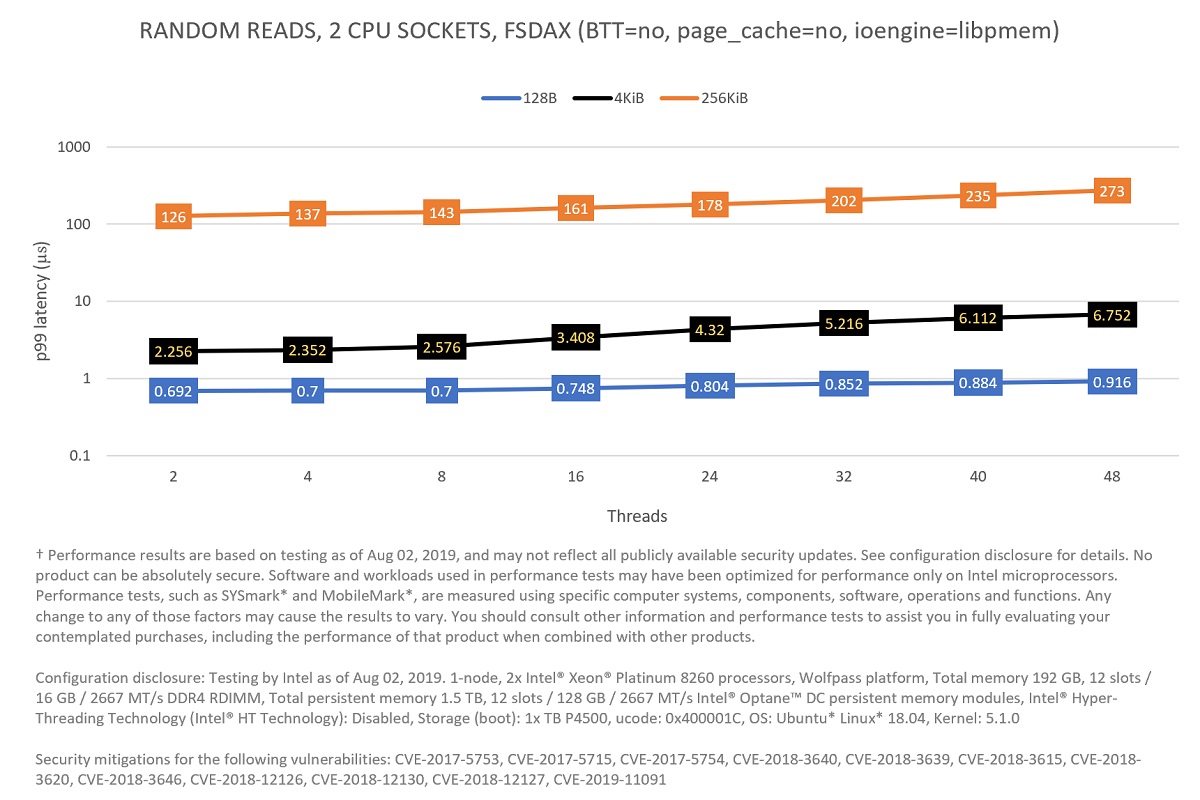
Figure 7: Comparing—in terms of p99 latency—block sizes for 100 percent random reads in two CPU sockets.
Figure 6 shows that the system can provide a read bandwidth of up to 70.6 GiB/s for random large accesses (256 KiB) using 40 threads (20 in each CPU socket), demonstrating that Intel Optane persistent memory modules can also alleviate workloads constrained by I/O bandwidth.
The Importance of Huge Pages
Given that all I/O accesses in persistent memory are memory copies, they are done through the virtual memory system. If the amount of memory to map is very large (with Intel Optane persistent memory, this can be up to 3 terabytes (TB) per socket), and the page size used by the OS is small (4KiB), we can encounter performance limitations with memory mapping from userspace due to the size of the page table that the OS needs to build. This can be alleviated if 2 mebibyte (MiB)—that is huge—pages (or bigger) are used. For more information, refer to the article I/O Alignment Considerations.
To visualize this, I run a set of experiments comparing a 2MiB-aligned partition versus a not 2MiB-aligned one for random reads. In the latter, the OS falls back to small, that is, 4 KiB pages.
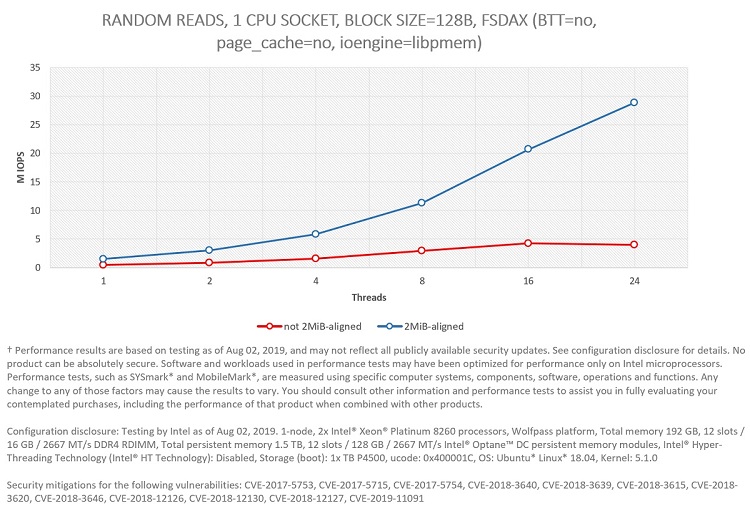
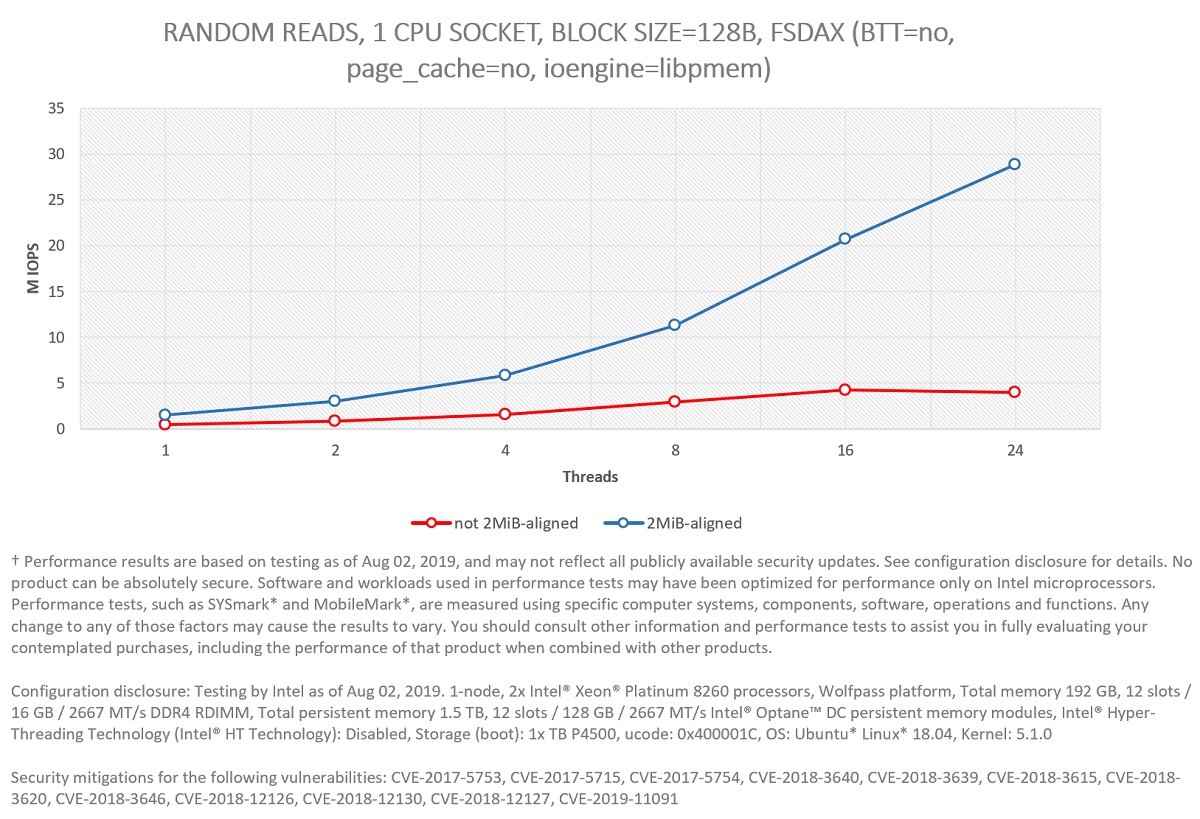
Figure 8: Performance difference between using a mapping with 2MiB-aligned pages versus not 2MiB-aligned.
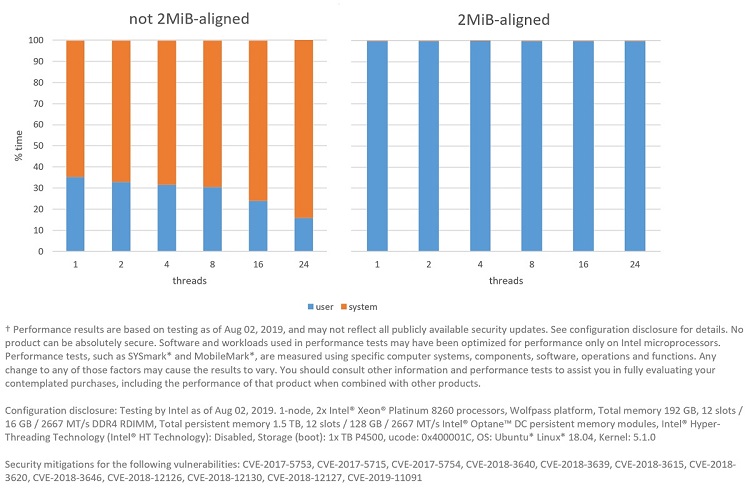
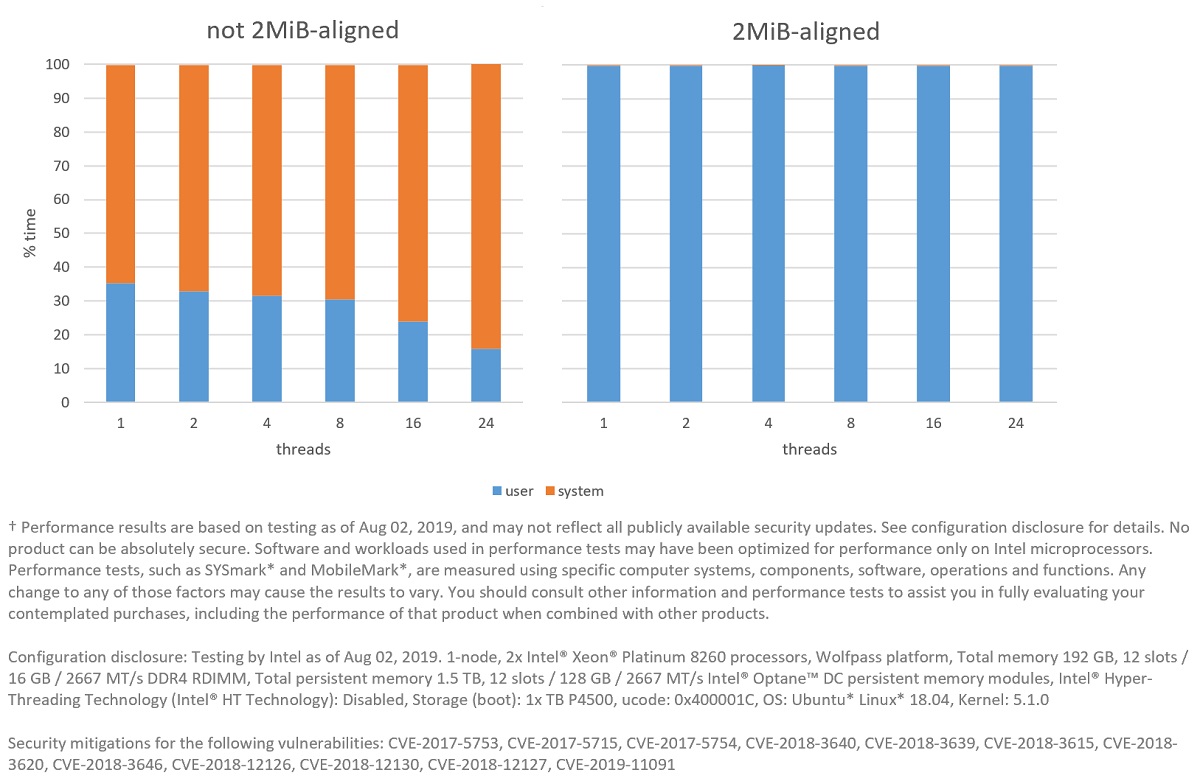
Figure 9: Amount of time FIO spends running in user and system modes between a mapping with 2MiB-aligned pages versus not 2MiB-aligned.
The performance impact can be seen in Figure 8. In Figure 9 we can see why: all experiments spend a significant amount of time in the OS allocating and zeroing the physical pages, as well as building the page table. This was confirmed by running perf to check the stack trace, which gives us information about where the execution spent most of its time. Figure 10 presents a graph generated by the FlameGraph tool showing this data.
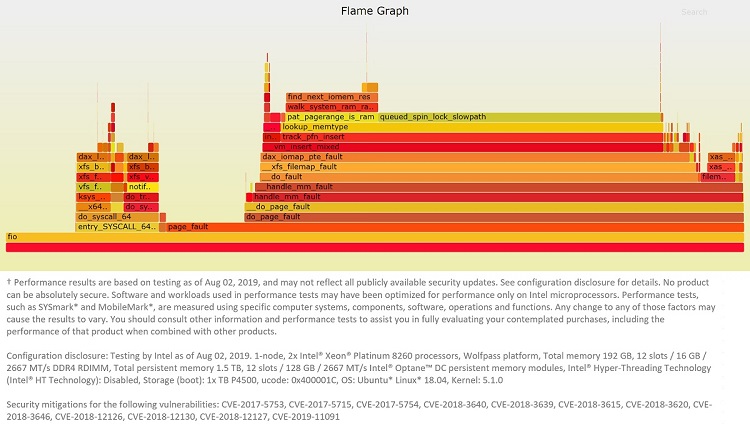
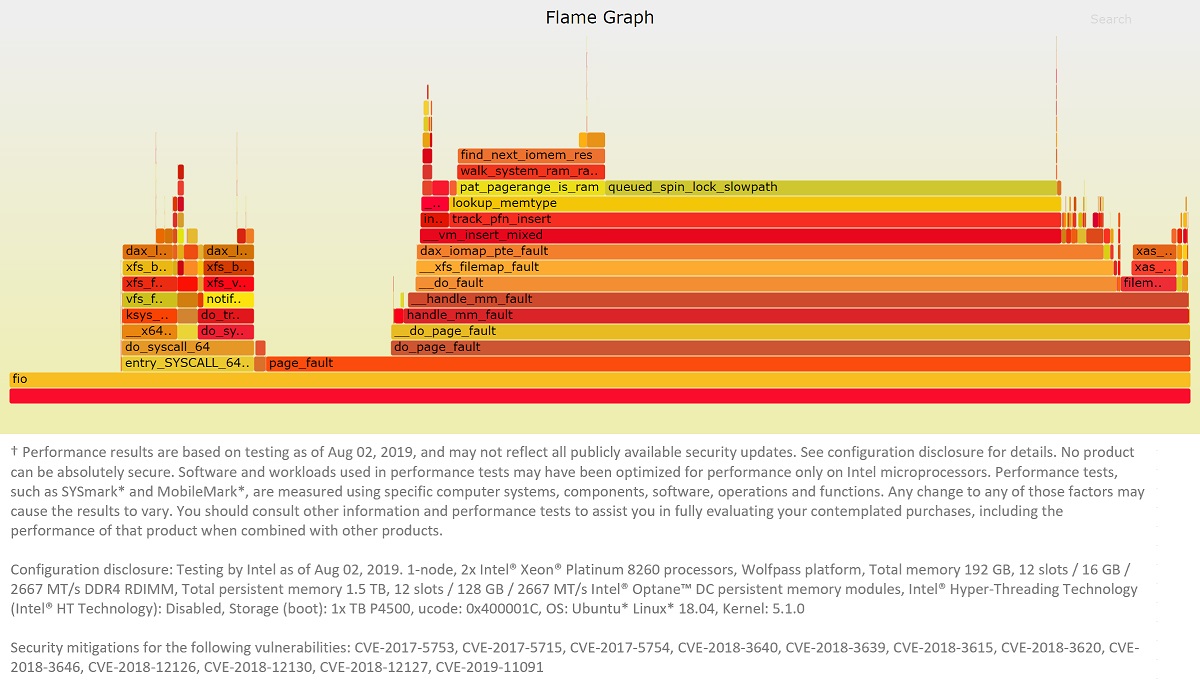
Figure 10: FlameGraph representation of perf data for the 24-thread experiment with the not 2MiB-aligned mapping.
As you can see, a substantial amount of the total run time is spent in page_fault. It should be mentioned that this is only an issue the first time the pages are accessed, therefore this may not be a problem if the file stays mapped for a long time. In that case, the application can warm up the page table by sequentially accessing all the mapped pages before proper workload execution starts.
Summary
In this article, I described how persistent memory can work as a substitute for traditional storage media such as HDDs or SSDs to speed up your I/O workloads. In the second part of the article, some performance numbers were presented comparing the different ways to do I/O and showcasing the impressive performance that can be achieved with Intel Optane persistent memory. At the end, one last set of experiments was presented that demonstrated the importance of using huge pages when memory mapping from userspace.
Footnotes
- With some exceptions, like in the case of systems with Intel® I/O Acceleration Technology (Intel® I/OAT).
- Using O_DSYNC on open() should improve performance a little bit. O_DSYNC was not used in these tests because, at the time of writing, it is not available with FIO.
- 99% of accesses have a latency equal to or lower than p99.
Appendix A: FIO Configuration File
Note: The libpmem engine implementation in FIO (at least for versions up until commit fc22034) is incorrect. The write path of the engine that uses non-temporal stores does not execute the SFENCE instruction at the end to ensure persistence is achieved after the write is completed. For proper testing, the following patch needs to be applied.
For brevity, only the FIO configuration file used for two CPU sockets is shown. To run with one socket, just delete one of the pnode sections.
[global]
name=fio-rand
rw=randrw
rwmixread=${RWMIX}
norandommap=1
invalidate=0
bs=${BLOCKSIZE}
numjobs=${THREADS}
time_based=1
clocksource=cpu
ramp_time=30
runtime=120
group_reporting=1
ioengine=${ENGINE}
iodepth=1
fdatasync=${FDATASYNC}
direct=${DIRECT}
sync=${SYNC}
[pnode0]
directory=${MOUNTPOINTSOCKET0}
size=630G
filename=file1.0.0:file1.0.1:file1.0.2:...:file1.0.62
file_service_type=random
nrfiles=63
cpus_allowed=0-23
[pnode1]
directory=${MOUNTPOINTSOCKET1}
size=630G
filename=file1.0.0:file1.0.1:file1.0.2:...:file1.0.62
file_service_type=random
nrfiles=63
cpus_allowed=24-47
The following parameters were used to test the different modes in the experiments presented in Figures 3 and 4:
| mode | Engine | fdatasync | Direct | Sync | |
|---|---|---|---|---|---|
 |
sector (BTT=yes, page_cache=yes, ioengine=psync) | psync | 1 | 0 | 0 |
| sector (BTT=yes, page_cache=no, ioengine=psync) | psync | 1 | 1 | 0 | |
 |
fsdax (BTT=no, page_cache=yes, ioengine=psync) | psync | 1 | 0 | 0 |
| fsdax (BTT=no, page_cache=no, ioengine=psync) | psync | 1 | 0 | 0 | |
| fsdax (BTT=no, page_cache=no, ioengine=libpmem) | libpmem | 0 | 1 | 1 | |
Appendix B: XFS Configuration
Formatting and mounting are shown for one socket only.
Without dax:
# mkfs.xfs -f -i size=2048 -d su=2m,sw=1 /dev/pmemXYZ
...
# mount -t xfs -o noatime,nodiratime,nodiscard /dev/pmemXYZ /mountpoint
# xfs_io -c "extsize 2m" /mountpoint
With dax:
# mkfs.xfs -f -i size=2048 -d su=2m,sw=1 -m reflink=0 /dev/pmemXYZ
...
# mount -t xfs -o noatime,nodiratime,nodiscard,dax /dev/pmemXYZ /mountpoint
# xfs_io -c "extsize 2m" /mountpoint
Notices
† Performance results are based on testing as of Aug 02, 2019, and may not reflect all publicly available security updates. See configuration disclosure for details. No product can be absolutely secure. Software and workloads used in performance tests may have been optimized for performance only on Intel microprocessors. Performance tests, such as SYSmark* and MobileMark*, are measured using specific computer systems, components, software, operations and functions. Any change to any of those factors may cause the results to vary. You should consult other information and performance tests to assist you in fully evaluating your contemplated purchases, including the performance of that product when combined with other products.
Configuration disclosure: Testing by Intel as of Aug 02, 2019. 1-node, 2x Intel® Xeon® Platinum 8260 processors, Wolfpass platform, Total memory 192 GB, 12 slots / 16 GB / 2667 MT/s DDR4 RDIMM, Total persistent memory 1.5 TB, 12 slots / 128 GB / 2667 MT/s Intel® Optane™ persistent memory modules, Intel® Hyper-Threading Technology (Intel® HT Technology): Disabled, Storage (boot): 1x TB P4500, ucode: 0x400001C, OS: Ubuntu* Linux* 18.04, Kernel: 5.1.0
Security mitigations for the following vulnerabilities: CVE-2017-5753, CVE-2017-5715, CVE-2017-5754, CVE-2018-3640, CVE-2018-3639, CVE-2018-3615, CVE-2018-3620, CVE-2018-3646, CVE-2018-12126, CVE-2018-12130, CVE-2018-12127, CVE-2019-11091
Intel technologies’ features and benefits depend on system configuration and may require enabled hardware, software or service activation. Performance varies depending on system configuration. Check with your system manufacturer or retailer or learn more at intel.com.
No license (express or implied, by estoppel or otherwise) to any intellectual property rights is granted by this document.
Intel disclaims all express and implied warranties, including without limitation, the implied warranties of merchantability, fitness for a particular purpose, and non-infringement, as well as any warranty arising from course of performance, course of dealing, or usage in trade.
This document contains information on products, services and/or processes in development. All information provided here is subject to change without notice. Contact your Intel representative to obtain the latest forecast, schedule, specifications and roadmaps.
The products and services described may contain defects or errors known as errata which may cause deviations from published specifications. Current characterized errata are available on request.
Copies of documents which have an order number and are referenced in this document may be obtained by calling 1-800-548-4725 or by visiting www.intel.com/design/literature.htm.